Abstract
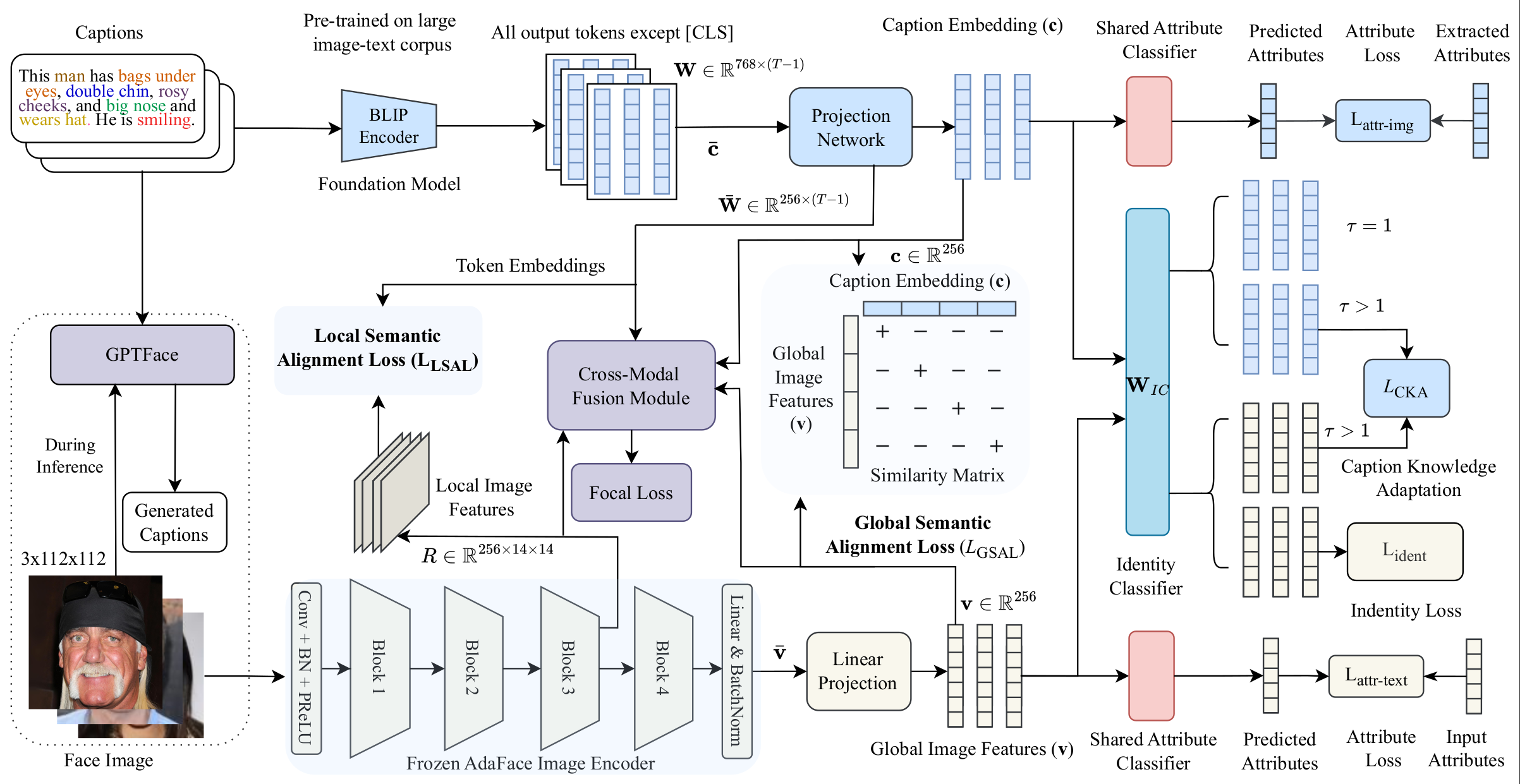
Text-guided face recognition (TGFR) aims to improve the performance of state-of-the-art face recognition (FR) algorithms by incorporating auxiliary information, such as distinct facial marks and attributes, provided as natural language descriptions. Current TGFR algorithms have been proven to be highly effective in addressing performance drops in state-of-the-art FR models, particularly in scenarios involving sensor noise, low resolution, and turbulence effects. Although existing methods explore various algorithms using different cross-modal alignment and fusion techniques, they encounter practical limitations in real-world applications. For example, during inference, textual descriptions associated with face images may be missing, lacking crucial details, or incorrect. Furthermore, the presence of inherent modality heterogeneity poses a significant challenge in achieving effective cross-modal alignment. To address these challenges, we introduce CaptionFace, a TGFR framework that integrates GPTFace, a face image captioning model designed to generate context-rich natural language descriptions from low-resolution facial images. By leveraging GPTFace, we overcome the issue of missing textual descriptions, expanding the applicability of CaptionFace to single-modal FR datasets. Additionally, we introduce a multi-scale feature alignment (MSFA) module to ensure semantic alignment between face-caption pairs at different granularities. Furthermore, we introduce an attribute-aware loss and perform knowledge adaptation to specifically adapt textual knowledge from facial features. Extensive experiments on three face-caption datasets and various unconstrained single-modal benchmark datasets demonstrate that CaptionFace significantly outperforms state-of-the-art FR models and existing TGFR approaches.
Overview
CaptionFace extends our earlier WACV 2024 work, TGFR, with a deeper alignment module, a knowledge-distillation mechanism between modalities, an attribute-aware objective, and an end-to-end captioning model that removes the framework's dependence on having a caption available at inference time. It is evaluated on three face-caption datasets (Multi-Modal CelebA-HQ, Face2Text, CelebA-Dialog), on single-modal benchmark FR datasets (LFW, CALFW, AgeDB-30) using captions generated on the fly, and on a fine-grained image classification benchmark (CUB-200-2011) to show the alignment module generalizes beyond faces.
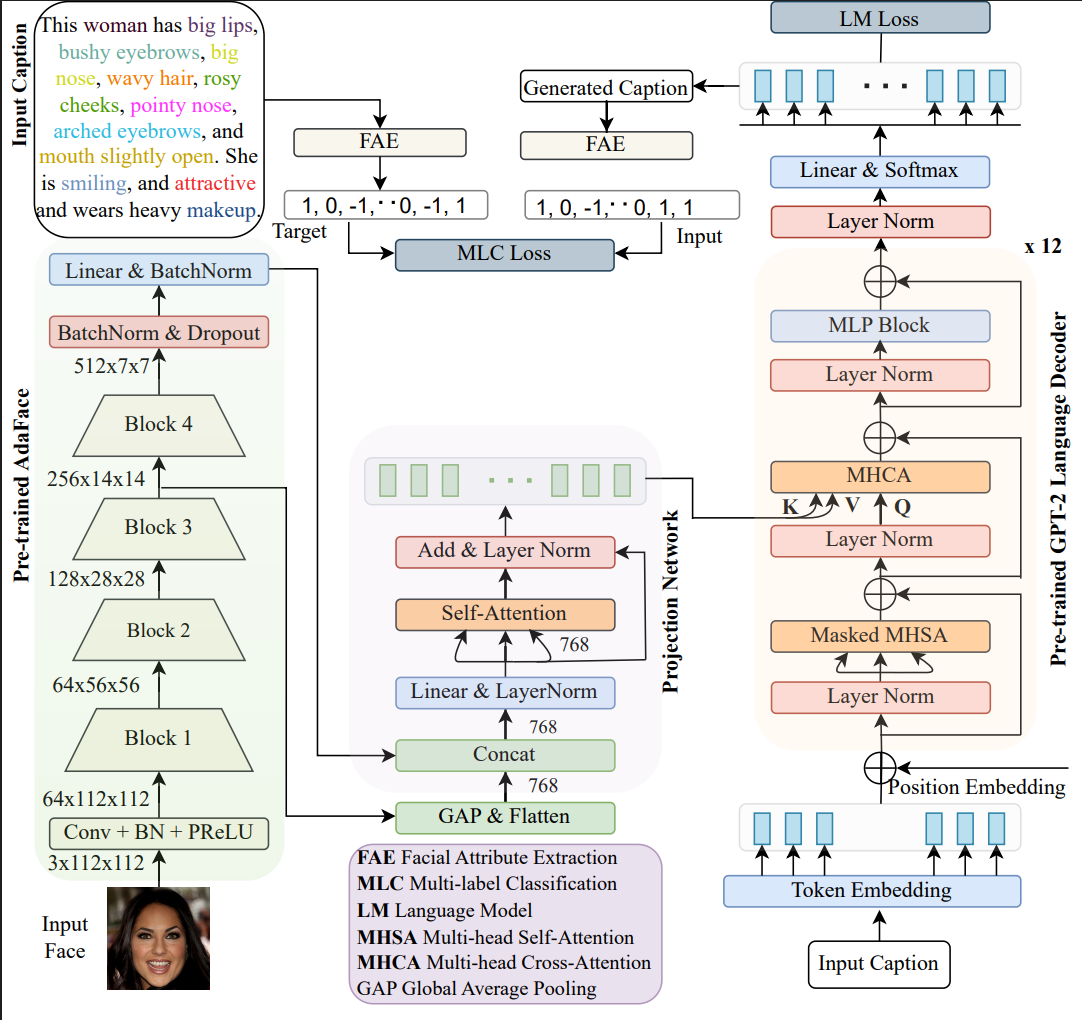
- Removes TGFR's dependence on ground-truth captions at inference time, via GPTFace.
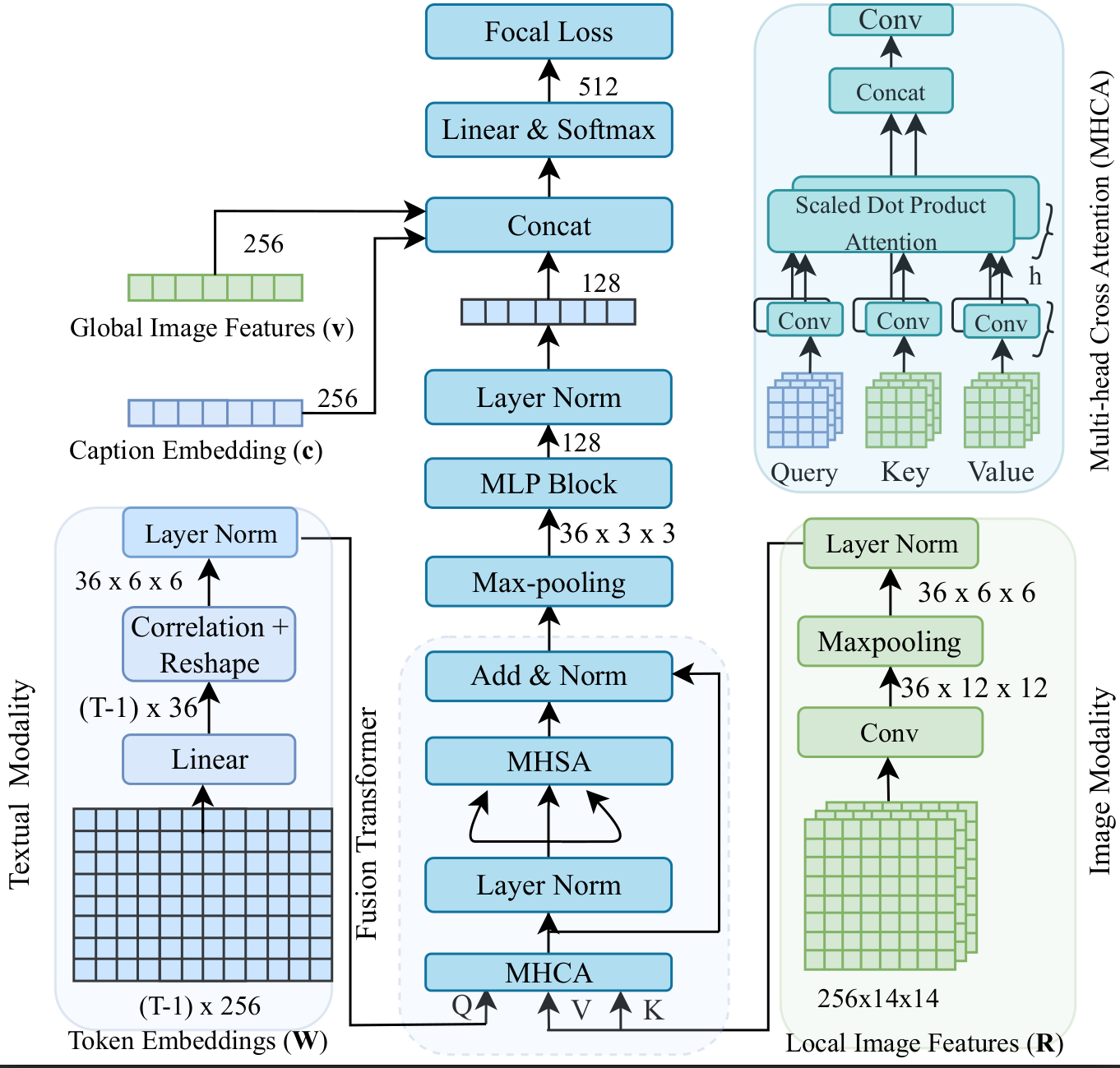
- Local + global contrastive alignment (MSAM), instead of one coarse image–text contrastive loss.
- Caption Knowledge Adaptation distills image-specific detail into text embeddings without polluting them with a direct identity loss.
- An attribute-aware loss adds a modality-invariant, fine-grained supervisory signal on top of identity loss.
- Consistently outperforms ArcFace, AdaFace, MagFace, and our own TGFR baseline across three face-caption datasets and three FR benchmarks.
- GPTFace matches BLIP / BLIP-2 captioning quality at roughly one-third the input resolution and a fraction of the parameter count (177M vs. 446M / 1.1B).